Recalling the Leslie Lamport quote about the essence of a distributed system:
“You know you have a distributed system when the crash of a computer you’ve never heard of stops you from getting any work done.”
Substitute certification authority for “computer” and trust established for “work done,” and we have a good description of current PKI infrastructure. The fragility of this model, which has inspired critics such as Peter Guttman for over a decade now, was demonstrated again in the latest TurkTrust debacle. Here are the salient facts:
- TurkTrust is a certification authority, present in Windows and NSS trusted root stores. Virtually all web browsers recognize this organization as valid issuer of SSL certificates used for secure connections on the web.
- TurkTrust issued two leaf certificates to websites with the “CA” property set to true. In other words, the lucky recipients became intermediate certification authorities themselves, inheriting all the privileges afforded TurkTrust by web browsers to mint the equivalent of identity papers for any website in the world.
- The intermediate CAs were used to issue fraudulent certificates, which were then used to falsely impersonate legitimate websites and intercept user traffic.
- The problem was not discovered internally by TurkTrust during audits. Instead it was caught by Google, thanks to the Chrome certificate pinning feature.
There are a number of details lacking satisfactory explanation, in spite of a decent attempt at postmortem by TurkTrust. Leaving aside those questions, there are two fundamental questions around why the mistake was possible:
- Why is TurkTrust– a CA based in Turkey and doing the majority of its business with companies Turkey– entrusted with issuing certificates for any company based anywhere in the world? This speaks to a profound breakdown of compartmentalization in X509, of any semblance of containing the failure of one component in the system from spreading to all others.
- Why does a single mistake in using the wrong certificate template result in random website owners getting unfettered CA privileges, with no other checks and balances?
It turns out the X509 standard already has provisions to help out with both. Not surprisingly, these features have not been used properly in the PKI system that emerged over the years.
The solution to the first problem is name constraints. If the CA certificate contains this particular property, it can only issue for websites with name matching the specified pattern. The natural restriction for TurkTrust would be requiring that the site name ends in “.TR”, indicating the top-level country domain for Turkey. Design of these constraints allow specifying both permitted and disallowed names. For example if some subdomain of TR was particularly sensitive, it can be further protected against TurkTrust errors by excluding that pattern. Incidentally, name constraints are propagated down the chain. Even if a bumbling CA accidentally creates a subordinate CA lacking any name constraints, the restrictions specified in the root still apply.
The solution to the second problem is path-length constraints. Any CA certificate can express a requirement to the effect certificate chains leading up to that point will be no longer than some fixed number of hops. Setting the limit to 1 hop prevents any “accidental” intermediate CA from being operational. Leaf certificates issued from that unintended intermediary would have an additional hop to the root CA, violating the path-length constraint.
Realistically neither extension has been used in practice for existing trust anchor. Few carry any name or path-length constraints, with the exception of subordinate CAs issued to companies such as Microsoft to issue their own certificates for their own domains. Understandably it is not in the interest of the CA to impose restrictions on itself– what if TurkTrust later wanted to expand its business into another country or create additional subordinate CAs? A less draconian requirement is that all leaf-certificates must be issued from an intermediate CA that has a path-length constraint of one. Since the key used to sign leaf certificates must be online, in the sense of being available in the normal course of business, it is at highest risk of “accidents.” While the path constraint does not prevent issuing mistakes, such incidents will be isolated to a small number of sites each time. (Granted when that site is Microsoft or Google, the mistake can have large repercussions.) One could also envision separate intermediaries for different top-level domains, but this is unlikely to reduce overall risk. Most likely all of them will run on same infrastructure with same operational profile, having exactly the same vulnerabilities.
Given that the economics do not favor CAs to exercise self-discipline, the next best option is self-defense for users. Unfortunately that involves changes to certificate verification logic to artificially simulate the constraints. Windows cryptography API has some flexibility in limiting trust associated with root anchors, for example to remove ability to issue certificates for specific purpose such as code signing.
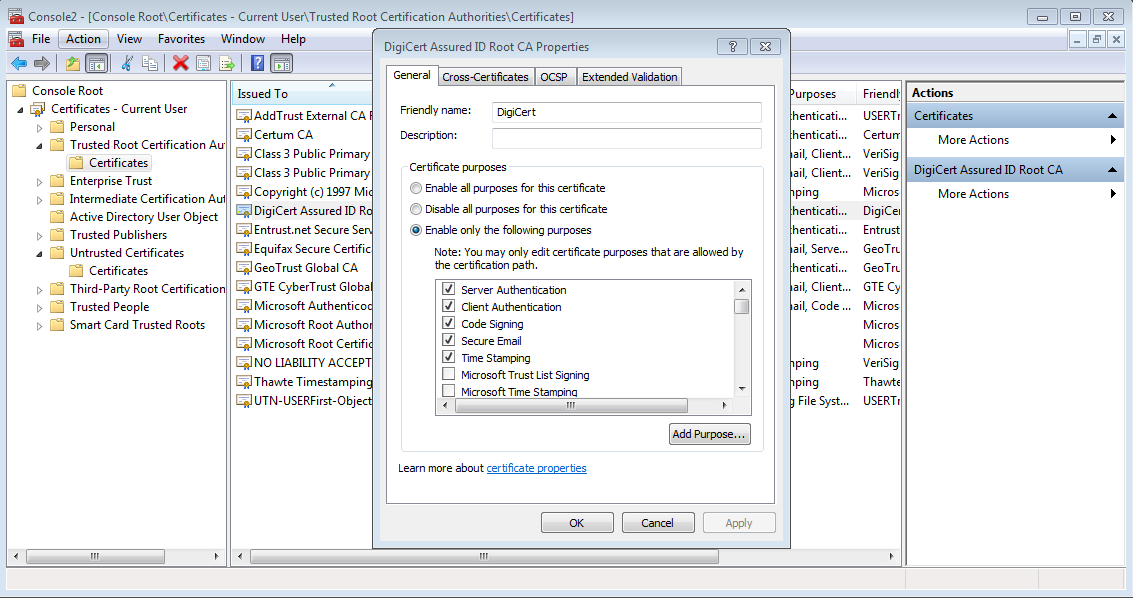
Editing properties using the management console
But that mechanism does not allow for introducing additional path or name constrains into an existing certification. (There is always the nuclear option of blacklisting a CA by putting them the Untrusted Certificates store but that goes well beyond the objective of “compartmentalizing” risk from CA failures.)
CP

You must be logged in to post a comment.