A critical take on Read-Write-Own
In the recently published “Read Write Own,” Chris Dixon makes the case that blockchains allow consumers to capture more of the returns from the value generated in a network because of the strongly enshrined rules of ownership. This is an argument about fairness: the value of networks is derived from the contributions of participants. Whether it is Facebook users sharing updates with their network or Twitter/X influencers opining on latest trends, it is Metcalfe’s law that allows these systems to become so valuable. But as the history of social networks has demonstrated time and again, that value accrues to a handful of employees and investors who control the company. Not only do customers not capture any of those returns (hence the often used analogy of “sharecroppers” operating on Facebook’s land) they are stuck with the negative externalities, including degraded privacy, disinformation and in the case of Facebook, repercussions that spill out into the real-world including outbreaks of violence.
The linchpin of this argument is that blockchains can guarantee ownership in ways that the two prevailing alternatives (“protocol networks” such as SMTP or HTTP and the better-known “corporate networks” such as Twitter) can not. Twitter can take away any handle, shadow-ban the account or modify their ranking algorithms to reduce its distribution. By comparison if you own a virtual good such as some NFT issued on a blockchain, no one can interfere with your rightful ownership of that asset. This blog post delves into some counterarguments on why this sense of ownership may prove illusory in most cases. The arguments will run from the least-likely and theoretical to most probably, in each case demonstrating ways these vaunted property rights fail.
Immutability of blockchains
The first shibboleth that we can dispense with is the idea that blockchains operate according to immutable rules cast in stone. An early dramatic illustration of this came about in 2016, as a result of the DAO attack on Ethereum. The DAO was effectively a joint investment project operated by a smart-contract on the Ethereum chain. Unfortunately that contract had a serious bug, resulting in a critical security vulnerability. An attacker exploited that vulnerability to drain most of the funds, to the tune of $150MM USD notional at the time.
This left the Ethereum project with a difficult choice. They could double down on the doctrine that Code-Is-Law and let the theft stand: argue that the “attacker” did nothing wrong, since they used the contract in exactly the way it was implemented. (Incidentally, that is a mischaracterization of the way Larry Lessig intended that phrase. “Code and other laws of cyberspace” where the phrase originates was prescient in warning about the dangers in allowing privately developed software, or “West Coast Code” as Lessig termed it, to usurp democratically created laws or “East Coast Code” in regulating behavior.) Or they could orchestrate a difficult, disruptive hard-fork to change the rules governing the blockchain and rewrite history to pretend the DAO breach never occurred. This option would return stolen funds back to investors.
Without reopening the charged debate around which option was “correct” from an ideological perspective, we note the Ethereum foundation emphatically took the second route. From the attacker perspective, their “ownership” of stolen ether proved very short lived.
While this episode demonstrated the limits of blockchain immutability, it is also the least relevant to the sense of property rights that most users are concerned about. Despite fears that the DAO rescue could set a precedent and force the Ethereum foundation to repeatedly bailout vulnerable projects, no such hard-forks followed. Over the years much larger security failures occurred on Ethereum (measured in notional dollar value) with the majority attributed with high confidence to rogue states such as North Korea. None of them merited so much as a serious discussion of whether another hard-fork is justified to undo the theft and restore the funds to rightful owners. If hundreds of million dollars in tokens ending up in the coffers of a sanctioned state does not warrant breaking blockchain immutability, it is fair to say the average NFT holder has little reason to fear that some property dispute will result in blockchain-scale reorganization that takes away their pixelated monkey images.
Smart-contract design: backdoors and compliance “features”
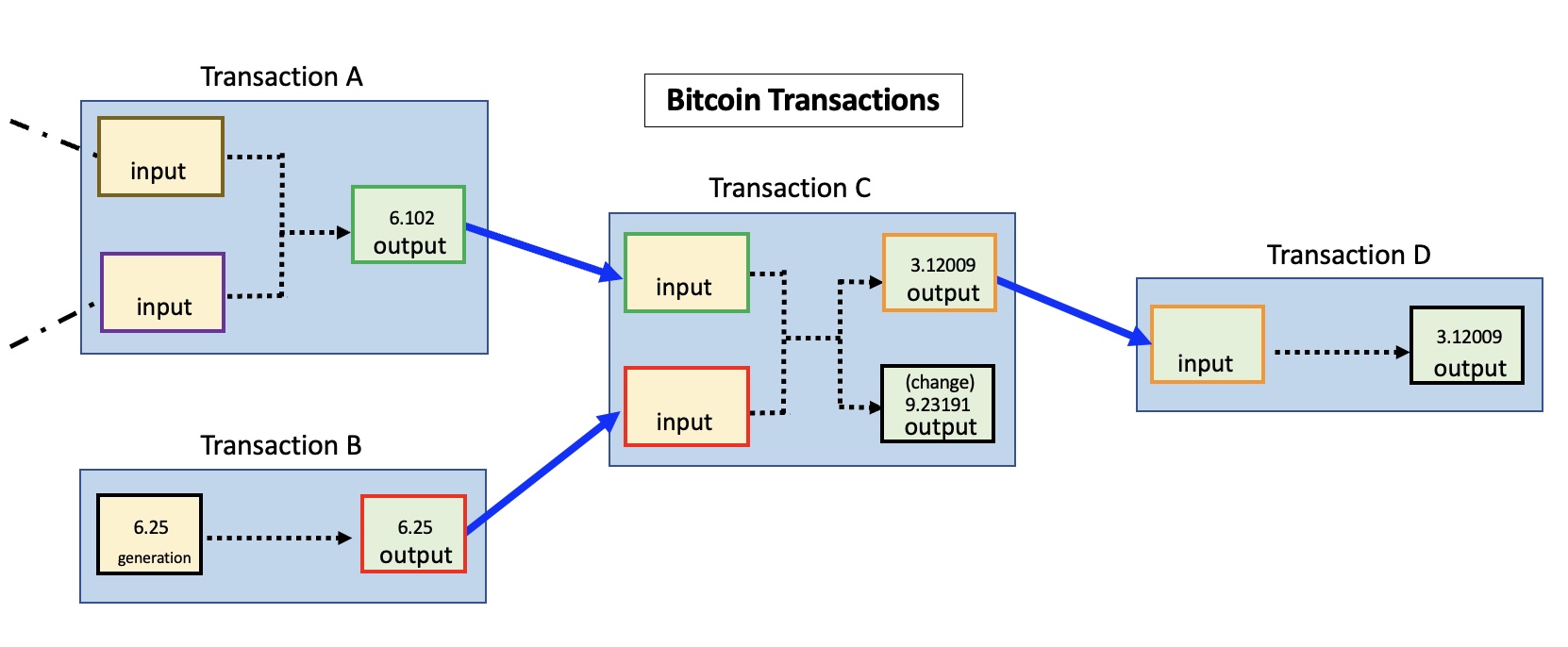
Much more relevant to the threat model of a typical participant is the way virtual assets are managed on-chain: using smart-contracts that are developed by private companies and often subject to private control. Limiting our focus to Ethereum for now, recall that the only “native” asset on chain is ether. All other assets such as fungible ERC-20 tokens and collectible NFTs must be defined by smart contracts, in other words software that someone authors. Those contracts govern the operation of the asset: conditions under which it can be “minted”— in other words, created out of thin air—transferred or destroyed. To take a concrete example: a stablecoin such as Circle (USDC) is designed to be pegged 1:1 to the US dollar. More USDC is issued on chain when Circle the company receives fiat deposits from a counterparty requesting virtual assets. Similarly USDC must be taken out of circulation or “burned” when a counterparty returns their virtual dollars and demands ordinary dollars back in a bank account.
None of this is surprising. As long the contract properly enforces rules around who can invoke those actions on chain, this is exactly how one envisions a stablecoin to operate. (There is a separate question around whether the 1:1 backing is maintained, but that can only be resolved by off-chain audits. It is outside the scope of enforcement by blockchain rules.) Less appreciated is the fact that most stablecoins contracts also grant the operator ability to freeze funds or even seize assets from any participant. This is not a hypothetical capability; issuers have not shied away from using it when necessary. To pick two examples:
- Circle froze $63 million linked to a theft from Multichain.
- Even Tether, known for its checkered history on compliance, froze $225 million linked to human trafficking pursuant to a DOJ order.
While the existence of such a “backdoor” or “God mode” may sound sinister in general, these specific interventions are hardly objectionable. But it serves to illustrate the general point: even if blockchains themselves are immutable and arbitrary hard-forks a relic of the past, virtual assets themselves are governed not by “native” rules ordained by the blockchain, but independent software authored by the entity originating that asset. That code can include arbitrary logic granting the issuer any right they wish to reserve.
To be clear, that logic will be visible on-chain for anyone to view. Most prominent smart-contracts today have their source code published for inspection. (For example, here is the Circle USD contract.) Even if the contract did not disclose its source code, the logic can be reverse engineered from the low-level EVM bytecode available on chain. In that sense there should be no “surprises” about whether an issuer can seize an NFT or refuse to honor a transfer privately agreed upon by two parties. One could argue that users will not purchase virtual assets from issuers who grant themselves such broad privileges to override property rights by virtue of their contract logic. But that is a question of market power and whether any meaningful alternative exists for consumers who want to vote with their wallet. It may well become the norm that all virtual assets are subject to permanent control by the issuer, something users accept without a second thought much like the terms-of-use agreements one clicks through without hesitation when registering for advertising-supported services. The precedent with stablecoins is not encouraging: Tether and Circle are by far the two largest stablecoins by market capitalization. The existence of administrative overrides in their code was no secret. Even multiple invocations of that power has not resulted in a mass exodus of customers into alternative stablecoins.
When ownership rights can be ignored
Let’s posit that popular virtual assets will be managed by “fair” smart-contracts without designed-in backdoors that would enable infringement of ownership rights. This brings us to the most intractable problem: real-world systems are not bound by ownership rights expressed on the blockchain.
Consider the prototypical example of ownership that proponents argue can benefit from blockchains: in-game virtual goods. Suppose your game character has earned a magical sword after significant time spent completing challenges. In most games today, your ownership of that virtual sword is recorded as an entry in the internal database of the game studio, subject to their whims. You may be allowed to trade it, but only on a sanctioned platform most likely affiliated with the same studio. The studio could confiscate that item because you were overdue on payments or unwittingly violated some other rule in the virtual universe. They could even make the item “disappear” one day if they decide there are too many of these swords or they grant an unfair advantage. If that virtual sword was instead represented by an NFT on chain, the argument runs, the game studio would be constrained in these types of capricious actions. You could even take the same item to another gaming universe created by a different publisher.
On the face of it, this argument looks sound, subject to the caveats about the smart-contract not having backdoors. But it is a case of confusing the map with the territory. There is no need for the game publisher to tamper with on-chain state in order to manipulate property rights; nothing prevents the game software from ignoring on-chain state. On-chain state could very well reflect that you are the rightful owner of that sword while in-game logic refuses to render your character holding that object. The game software is not running on the blockchain or in any way constrained by the Ethereum network or even the smart-contract managing virtual goods. It is running on servers controlled by a single company— the game studio. That software may, at its discretion, consult the Ethereum blockchain to check on ownership assignments. That is not the same as being constrained by on-chain state. Just because the blockchain ledger indicates you are the rightful owner of a sword or avatar does not automatically force the game rendering software to depict your character with those attributes in the game universe. In fact the publisher may deliberately depart from on-chain state for good reasons. Suppose an investigation determines that Bob bought that virtual sword from someone who stole it from Alice. Or there have been multiple complaints about a user-designed avatar being offensive and violating community standards. Few would object to the game universe being rendered in a way that is inconsistent with on-chain ownership records under these circumstances. Yet the general principle stands: users are still subject to the judgment of one centralized entity on when it is “fair game” to ignore blockchain state and operate as if that virtual asset did not exist.
Case of the disappearing NFT
An instructive case of “pretend-it-does-not-exist” took place in 2021 when Moxie Marlinspike created a proof-of-concept NFT that renders differently depending on which website it is viewed from. Moxie listed the NFT on OpenSea, at the time the leading marketplace for trading NFTs. While it was intended in good spirit as a humorous demonstration of the mutability and transience of NFTs, OpenSea was not amused. Not only did they take down the listing, but the NFT was removed from the results returned by OpenSea API. As it turns out, a lot of websites rely on that API for NFT inventories. Once OpenSea ghosted Moxie’s API, it is as if the NFT did not exist. To be clear: OpenSea did not— and could not— make any changes to blockchain state. The NFT was still there on-chain and Moxie was its rightful owner as far as the Ethereum network is concerned. But once the OpenSea API started returning alternative facts, the NFT vanished from view for every other service relying on that API instead of directly inspecting the blockchain themselves. (It turns out there were a lot of them, further reinforcing Moxie’s critique of the extent of centralization.)
Suppose customers disagree with the policy of the game studio. What recourse do they have? Not much within that particular game universe, anymore than the average user has any leverage with Twitter or Facebook in reversing their trust & safety decisions. Users can certainly try to take the same item to another game but there are limits to portability. While blockchain state is universal, game universes are not. The magic sword from the medieval setting will not do much good in a Call Of Duty title set in WW2.
In that sense, owners of virtual game assets are in a more difficult situation than Moxie with his problematic NFT. OpenSea can disregard that NFT but can not preclude listing on competing marketplaces or even arranging private sales to a willing buyer who values it on collectible or artistic merits. It would be the exact same situation if OpenSea for some bizarre reason came to insist that you do not own a bitcoin that you rightfully own on blockchain. OpenSea persisting at such a delusion would not detract in any way from the value of your bitcoin. Plenty of sensible buyers exist elsewhere who can form an independent judgment about blockchain state and accept that bitcoin in exchange for services. But when the value of a virtual asset is determined primarily by its function within a single ecosystem— namely that of the game universe controlled by a centralized publisher— what those independent observers think about ownership status carries little weight.
CP
[Edited to correct grammar issues- May 2026]

You must be logged in to post a comment.