[Part of a series on getting by without passwords]
Next up in this series on using hardware tokens to replace passwords: disk encryption.
Threat models for disk encryption
One word of caution here: OS-based disk encryption, particularly on boot volumes, by itself is not sufficient unless also accompanied by another safeguard to ensure boot integrity such as UEFI secure boot, TPM-based measured boot etc. To motivate this, we distinguish two different threat models:
- Passive attack: This is the garden-variety lost/stolen laptop scenario. The device is captured by the adversary, who must contend with defeating disk encryption without ever interacting with the legitimate user or possessing their credentials. (In other words, no out-of-band tricks to get disk encryption passphrase.)
- Active attack or “evil-maid” scenario: Adversary gets access to the device, tampers with it and then returns it back to the owner. Oblivious to the fact that their device has been in nefarious hands, legitimate owner proceeds to power it on, decrypt the disk and use their machine as if nothing happened.
(It’s worth pointing out this dichotomy does not cover the full range of attacks. For example original cold-boot attacks did not require require interaction, but relied on a quirk of Bitlocker default configuration: decryption happens automatically on boot using TPM. It’s as if the “user” is always present and willing to type in a decryption passphrase whenever prompted.)
Disk encryption alone falls short in the second scenario, regardless of the strength of cryptography or strategy for managing decryption keys. The reason is that before disk can be decrypted, some other piece of the code must execute that is responsible for implementing that complex full-disk encryption logic. That typically resides on another partition, which itself can not be encrypted to avoid a turtles-all-the-way-down situation. Otherwise we need another piece of boot-strap code to decrypt that partition, in a turtles-all-the-way-down circularity. But it could also be part of the BIOS firmware. Now if an attacker can tamper with that code and have the user proceed to unlock the disk using their Trojaned version, they have effectively bypassed encryption: during the decryption, their malicious loader could directly inject a payload into the operating system by returning bogus plaintext. (“You are trying to decrypt sectors containing the sshd binary? Here, take this version instead which contains a backdoor that will grant your adversary remote access with a magic passphrase.”) This is why it is necessary to guarantee integrity of the entire boot chain, starting from the firmware to the multiple stages of the boot-loader, all the way until the operating system gains control.
With that disclaimer in mind, here is a proof-of-concept for using off-the-shelf cryptographic hardware for disk encryption.
First the two easy cases.
OSX
This has an easy answer, because of the limitations in OSX: existing FileVault design does not support interfacing with smart-cards. (For historical purposes: the current version is technically FileVault2. The original FileVault was based on a different design and did support smart-card unlock.)
Windows
Supporting hardware-based disk encryption on Windows is also very easy because it is already built-in. That said, we need to distinguish between two cases. Bitlocker for boot volumes does not use smart-cards. It can not; that scenario calls for specific TPM functionality, such as platform configuration registers or PCRs, to guarantee boot integrity which can not be emulated using an external token that is decoupled from the motherboard. Bitlocker-To-Go on the other hand, can use any compatible smart-card to encrypt other types of storage, such as additional logical partitions and even removable volumes such as USB thumb drives. It can even protect remote disks mounted as iSCSI targets and virtual-disk images, described in earlier posts around on using existing cloud-storage services without giving up privacy.
Linux with dm-crypt & LUKS
Linux falls into that gray area between OSX where enterprise-security scenarios usually don’t work because Apple never designed for enterprise, and Windows where the “common” scenario works out-of-the box provided one is adhering to the MSFT script. There is not a single “full-disk encryption” feature built into Linux but a wide array of choices, with only a handful used in practice.
This example describes implementing FDE using a PIV card with the popular LUKS and dm-crypt combination. dm-crypt operates at the level of block devices. Quoting from the cryptsetup wiki:
Device-mapper crypt target provides transparent encryption of block devices using the kernel crypto API. The user can basically specify one of the symmetric ciphers, an encryption mode, a key (of any allowed size), an iv generation mode and then the user can create a new block device in /dev. Writes to this device will be encrypted and reads decrypted. You can mount your filesystem on it as usual or stack dm-crypt device with another device like RAID or LVM volume.
LUKS in turn provides a layer for managing these encryption keys. LUKS can manage multiple “slots,” each containing versions of the encryption key protected by a different mechanism. One helpful property of this behavior is providing side-by-side support for traditional passwords along with smart-cards, using different slots. It also provides a migration path to switch from passwords to hardware tokens, simply by deleting the associated slot.
LUKS and smart-cards
LUKS by itself does not have a notion of smart-cards, cryptographic hardware or even high-level interfaces such as PKCS#11. Instead it comes with an even more general extensibility mechanism called key-scripts. This model allows specifying an arbitrary binary to be executed and use the stdout output from that binary as the decryption key for unlocking a volume. This is more than enough to implement support for smart-cards. (In fact it has also been used to implement a poor-man’s Bitlocker.)
Our strategy is:
- Generate a random symmetric key
- Create a LUKS key-slot containing this symmetric key
- We will not store the original symmetric key. Instead, we encrypt it using the public-key from one of the smart-card certificates. That resulting ciphertext is stored on disk.
- Write a custom LUKS keyscript to decrypt that ciphertext using the corresponding private-key from smart-card
- Configure LUKS to invoke that key-script when the partition needs to be unlocked.
Walk-through
Here is a more detailed walk-through the steps.
Caveat emptor: This is for illustration purposes only. In practice these steps would be automated, to avoid extended exposure of raw secrets in environment variables.
First generate a random secret:
RANDOM_KEY=`openssl rand -base64 32`
Next we assign it into one of the LUKS key slots:
cryptsetup luksAddKey /dev/sda2 <(echo "$RANDOM_KEY")
In this example /dev/sda2 is the partition containing an existing LUKS volume. The command must be run as root and will require one of the existing passphrases to be supplied. After the new key-slot is added, the disk can be unlocked anytime in the future by presenting that secret again.
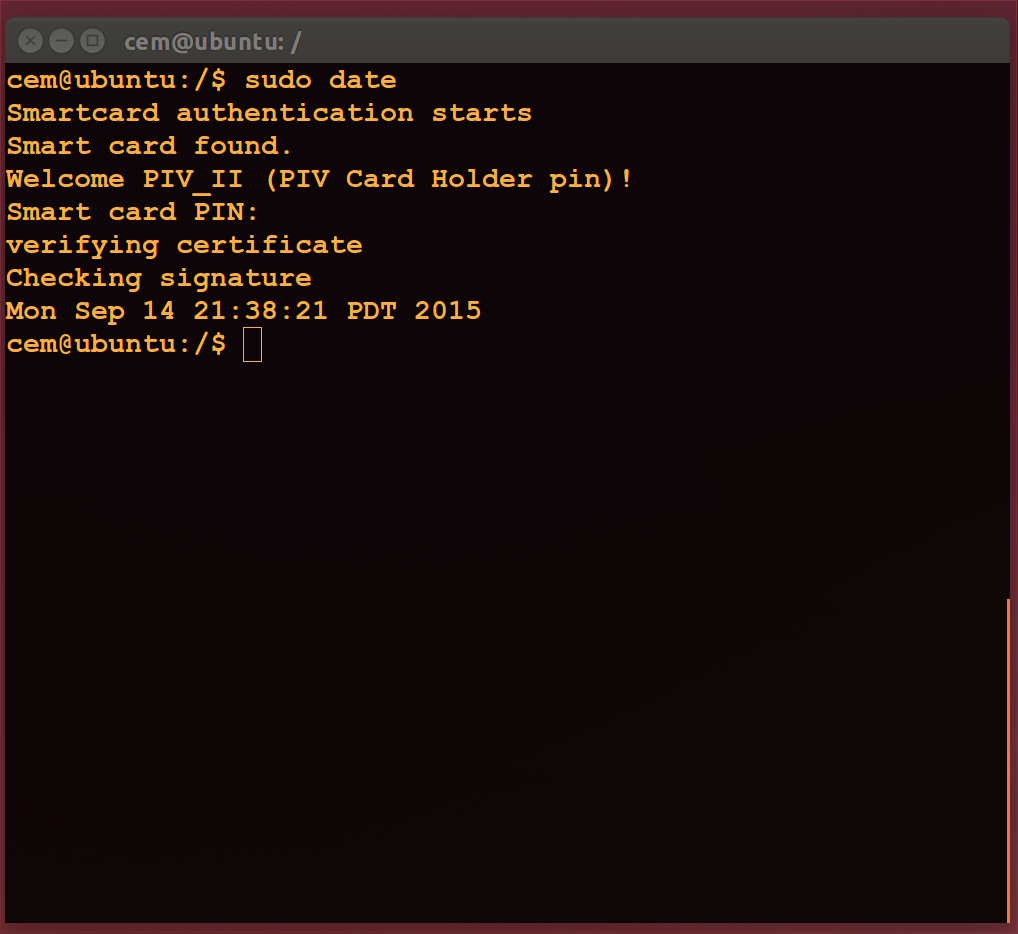
Tying unlock to a hardware token
The core idea is making that capability—“present original secret”— conditional on having control over the smart-card. This is achieved by encrypting the secret using one of the public keys associated with the card and throwing away the original. From now on, recovering that secret to unlock the disk requires performing the corresponding private-key operation to decrypt the ciphertext. Typically that translates into having possession of the card and knowing the associated PIN.
To encrypt, we retrieve a certificate from the card and extract the public key from it using openssl.
PUBLIC_KEY=`pkcs15-tool --read-certificate 01 |\ openssl x509 -inform PEM -noout -pubkey` openssl rsautl -encrypt -inkey <(echo "$PUBLIC_KEY") -pubin \ <<< $RANDOM_KEY > /crypto/fde_ciphertext.bin
Two ancillary notes about this:
- PIV standard defines multiple X509 certificate slots that may be present on the card. This example uses the PIV Authentication Certificate, via identifier “01.” (This is a synthetic ID created by OpenSC. There is no such mapping in PIV, where the card-edge assigns keys identifiers such as 0x9A, 0x9B etc.) Any other key that permits decryption could be used; in fact Key Management certificate is more in the spirit of disk encryption.
- Choice of raw RSA PKCS1.5 format is somewhat arbitrary and driven by convenience. (OAEP would have been preferable but at the time of writing, OpenSC does not grok OAEP, creating a challenge for decryption.) For the special case of managing LUKS secrets, more complex encryption modes such as CMS that use a random symmetric-key to bulk-encrypt data are not necessary. Entirety of the secret data to be protected fits in a single RSA block for contemporary key sizes.
Unlocking the volume
We store the ciphertext outside the encrypted partition to avoid a circularity; access to the ciphertext is necessary before we can unlock the partition. In this example /etc/crypto is used. In the same directory we also drop a key-script that will be used for unlocking the volume. This is a simple bash script to decrypt the ciphertext using the smart-card to recover the original secret, and output that to stdout for the benefit of LUKS.
Raw RSA decryption is performed by using pkcs15-crypt from OpenSC. We could also have used pkcs11-tool which has more options, but adds another moving part in having to locate the appropriate PKCS #11 module.**
Finally we adjust the crypttab file to invoke the custom key-script when unlocking our encrypted partition:
cem@ubuntu:/$ cat /etc/crypttab
# <target> <device> <key file> <options>
home /dev/sdb1 /crypto/fde_ciphertext.bin luks,keyscript=/crypto/unlock.sh
(Without a key-file or key-script, the default behavior is interactively prompting the user for a passphrase instead.)
CP
** In a way it is a fluke that pkcs15-tool works in this scenario; PIV is a distinct card-edge; it does not conform the PKCS #15 standard for what a card application looks like at the APDU level.



You must be logged in to post a comment.