[continued from part I: Introduction]
Exploit conditions
One question we have not addressed until now is the threat model. Typically before deriving related-keys and HMACing our chosen message, we have authenticate to the HSM. In the case of our Luna G5, that takes place out-of-band with USB tokens and PIN entered on external PIN-entry-device, or PED, attached to the HSM. For CloudHSM it uses a more rudimentary approach involving passwords sent by the client. (Consequently CloudHSM setup can only achieve level-2 security assurance in FIPS 140-2 evaluation criteria while PED-authenticated versions can achieve level-3.) Regardless of the authentication mode, the client must have a logged in session with HSM to use existing keys.. It is enough then for an attacker to compromise the client machine in order to extract keys. That may sound like a high barrier or even tautological- “if your machine is compromised, then your keys are also compromised.” But protecting against that outcome is precisely the reason for using cryptographic hardware in the first place. We offload key management to special-purpose, tamper-resistant HSMs because we do not trust our off-the-shelf PC to sufficiently resist attacks. The assumption is that even if the plain PC were compromised, attackers only have a limited window for using HSM keys and only as long as they retain persistence on the box, where they risk detection. They can not exfiltrate keys to continue using them after their access has been cut off. That property both limits damage and gives defenders time to detect/respond. A key extraction vulnerability such as this breaks that model. With a vulnerable HSM, temporary control over client (or HSM credentials, for that matter) allows permanent access to key outside the HSM.
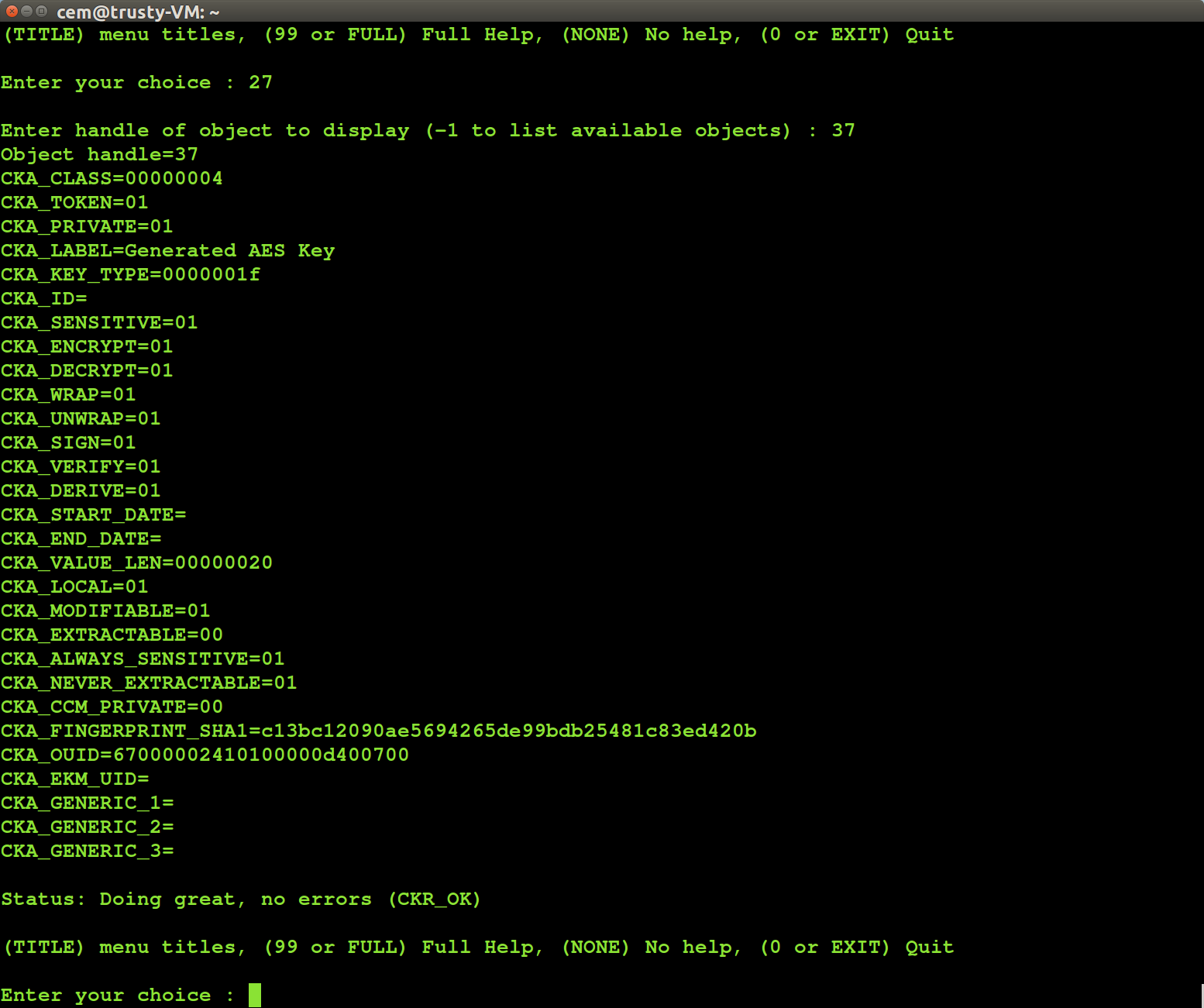
PKCS #11 object attributes
The vulnerability applies to all symmetric keys, along with elliptic curve private-keys. There is one additional criteria required for exploitation: the key we are trying to extract must permit key-derivation operations. PKCS#11 defines a set of boolean attributes associated with stored objects that describe usage restrictions. In particular CKA_DERIVE determines whether a key can be used for derivation. A meta-attribute CKA_MODIFIABLE determines whether other attributes (but not all of them) can be modified. Accordingly an object that has CKA_DERIVE true or CKA_MODIFIABLE true— which allows arbitrarily changing the former attribute— is vulnerable.
Surprisingly many applications create keys with all of these attributes enabled, even when the operation is not meaningful. For example the Java JSP provider for Safenet creates keys with modifiable attribute set to true, and all possible purposes enabled. If a Bitcoin key were generated using that interface, the result would support not only digital signature- which is the only meaningful operation for Bitcoin keys, as they are used to sign transactions- but also wrap/unwrap, decryption and key derivation. It requires using the low-level PKCS #11 API to correctly configure attributes according to the principle of least-privilege, with only intended operations enabled. In fairness, part of the problem is that the APIs can not express the concept of an “ECDSA key” at generation time. This is obvious for the generic Java cryptography API which uses a generic “EC” type for generating elliptic curve keys. The caller does not specify ahead of time the purpose that key is being generated. Similarly PKCS #11 does not differentiate based on object type but relies on attributes. A given elliptic-curve private key can be used in ECDSA for signing, ECDH key-agreement to derive keys or ECIES for public-key decryption depending on whether corresponding CKA_* attributes are set.
Mitigation
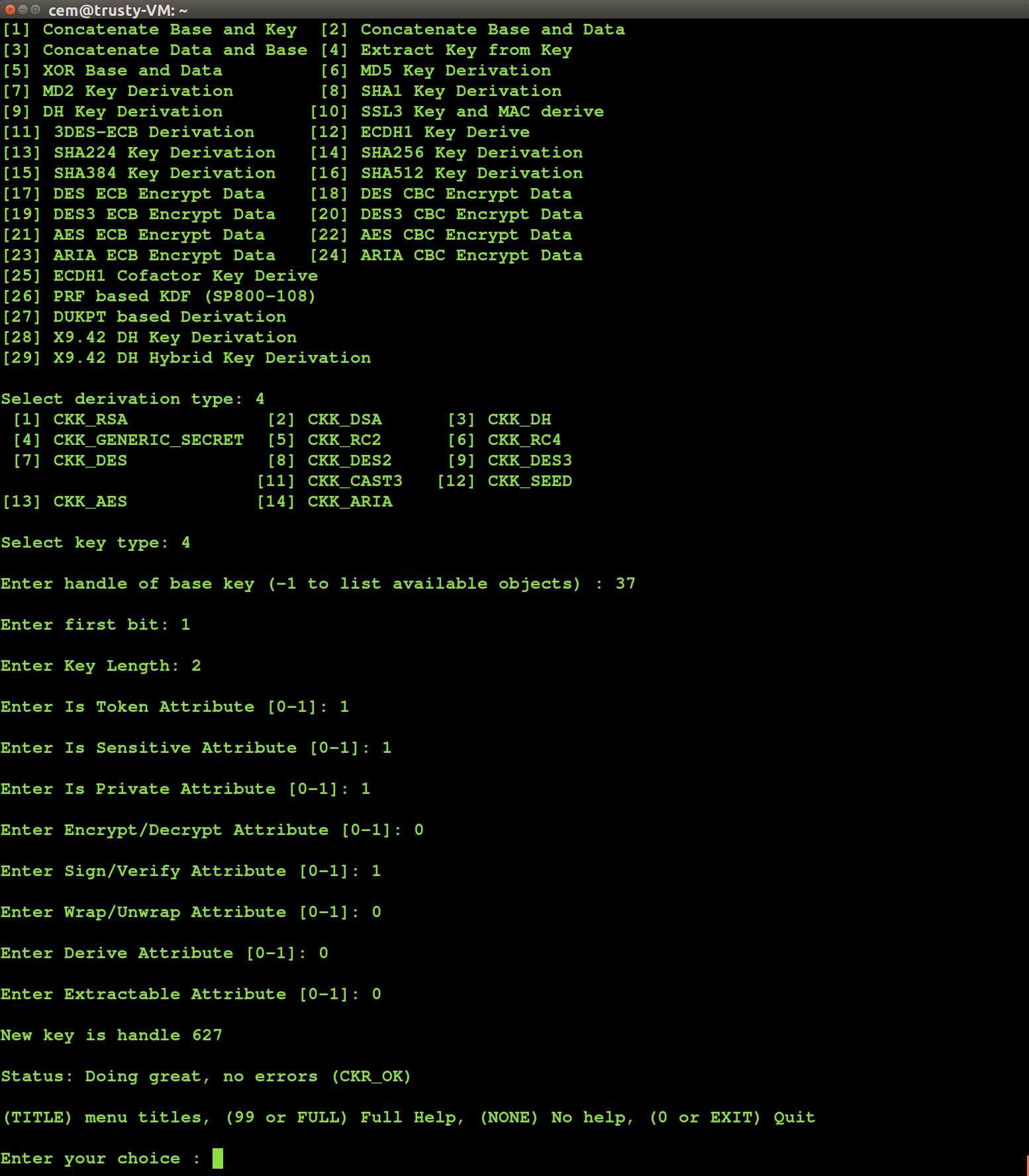
Latest firmware update from Safenet addresses the vulnerability by removing weak key-derivation schemes. This is the more cautious approach. It is preferable to incremental tweaks such as attempting to set a minimum key-length, which would not be effective. For example if the HSM still allowed extract-key-from-key but required a minimum of 16 bytes, one could trivially work around it: prepend (or append) known 15 bytes to an existing key, then extract the first (or last, respectively) 16 bytes. Nominally the derived key is 16 bytes long and satisfies the constraints. In reality all but one byte is known and brute-forcing this key is no more difficult than brute forcing a single byte.
Likewise it is tempting to blame the problem on extract-key-from-key but other bit-flipping and splicing mechanism are equally problematic. All of the weak KDF schemes permit “type-casting” keys between algorithms, allowing attacks against one algorithm to be applied to keys that were originally intended for a different one. For example an arbitrary 16-byte AES can not be brute-forced given state-of-the-art today. But suppose you append/prepend 8 known bytes to create a 3DES key, as Safenet HSMs permit with the concatenate mechanisms. (Side-note: Triple-DES keys are 21 bytes but they are traditionally represented using 24 bytes with least-significant bit reserved as parity check.) The result is a surprisingly weak key that can be recovered using a meet-in-the-middle attack with the same time complexity as recovering a single-DES key, albeit at the cost of using a significant amount of storage. Similarly XOR and truncation together can be used to recover keys by exploiting an unusual property of HMAC: appending a zero-byte to an HMAC key does not alter its outputs, up to the block size of the hash function. Even XOR alone without any truncation is problematic when applied to 3DES, where related-key attacks against the first and third subkey are feasible.
Workarounds using PKCS#11 attributes
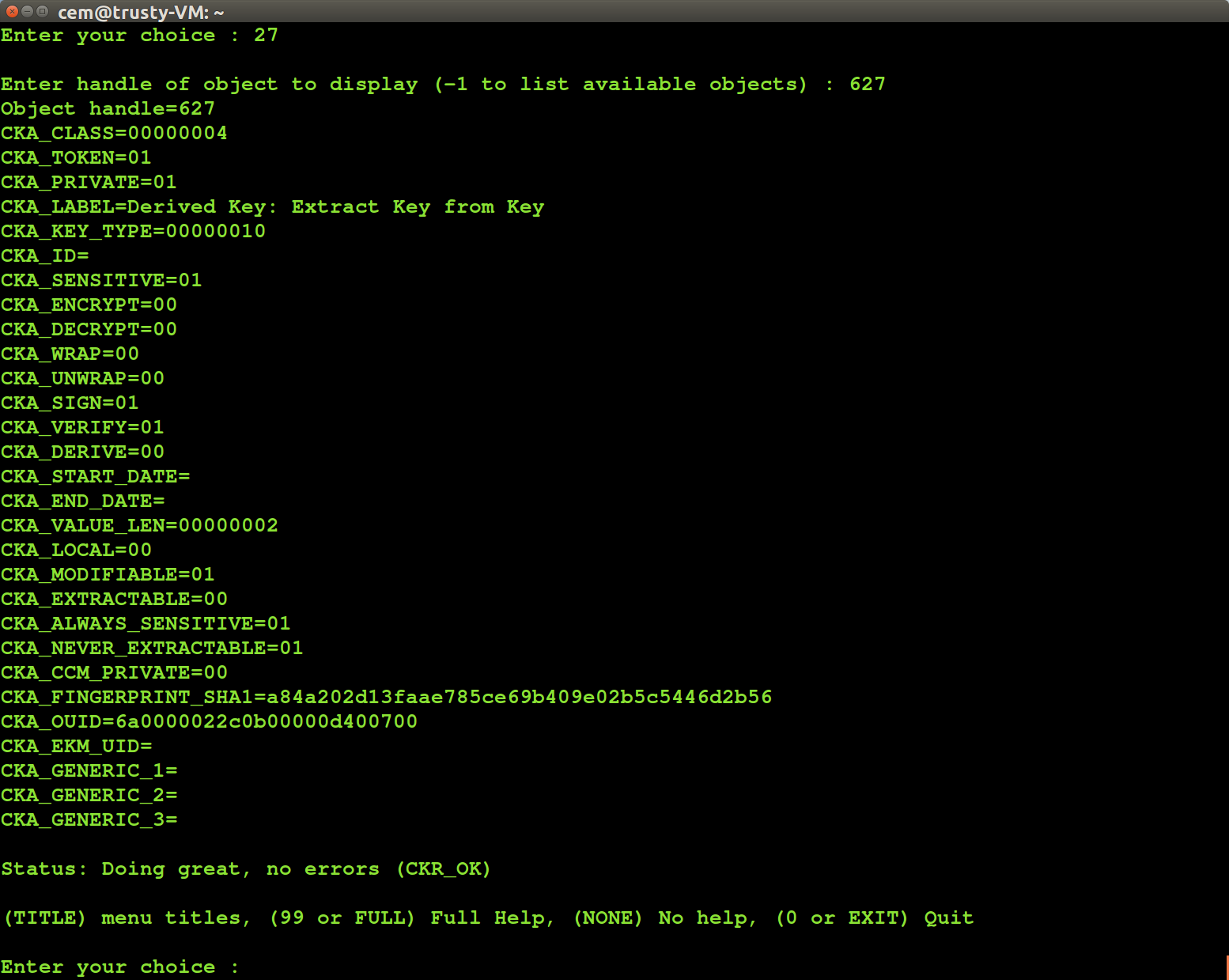
Since the attack relies on using key-derivation mechanisms, the following work-around seems natural for protecting existing keys: set CKA_DERIVE to false which will prevent the key from being used in derivation mechanism and also set CKA_MODIFIABLE to false, making the object “read-only” going forward. This does not work; the CKA_MODIFIDABLE attribute is immutable and determined at time of key generation. If the key was not generated with proper set of attributes, it can not be protected after the fact. But there is a slightly more complicated work-around that uses object cloning. While a modifiable object can not be “fused” into a read-only object, it is possible to duplicate it and assign new attributes to the clone. This is the one opportunity for changing CKA_MODIFIABLE attribute to false. (Incidentally the transition in the opposite direction is disallowed: it is not possible to make a modifiable clone of an object that started out being immutable.) That creates a viable work-around: duplicate all objects and set modifiable/derive attributes to false in the new copy, delete the original. Applications may have to be reconfigured to use the new copy, which will have a different numeric handle, but could retain same label as original, if keys were being looked-up by name.
One limitation of this approach is that some secrets are intended for key-derivation. For example that secp256k1 private-key could have been used for ECDH key-agreement. That operation happens to be considered “key-derivation” according PKCS#11. That means CKA_DERIVE can not be set to false without rendering the key unusable. Per-object policy does not distinguish between derivation mechanisms at a granular level.
FIPS to the rescue?
Safenet HSMs have an option to be configured in “strict-FIPS” mode. This setting is defined by administrator at HSM-level and disables certain weak algorithms. At first we were hopeful this could be the one time where FIPS demonstrably improves security by outright mitigating a vulnerability. That turns out not to be the case. Even though the documentation states that weak algorithms are “disallowed” in FIPS mode, the restrictions only come into play when using keys. For example HSM will still generate a single DES key in strict-FIPS mode; but it will refuse to perform single-DES encryption. As for the problematic key-derivation mechanisms at the heart of this vulnerability: they are still permitted, as is HMAC using very short secrets.
Even if strict-mode FIPS worked as expected, it is not practical for existing users. Switching FIPS policy is a destructive operation; all existing keys are deleted. Instead a more indirect operation is required: backup all keys to a dedicated backup device, switch FIPS setting and restore from the backup or another HSM. After all that trouble any defensive gains would still be short-lived: nothing prevents switching the FIPS mode back and restoring from backups again.
Residual risks: cloning
The same problem with backup-and-restore also applies to cloning. Safenet defines a proprietary replication protocol to copy keys from one unit to another, as long as they share certain configurations:
- Both HSMs must have same authentication mode: eg password-authenticated (FIPS 140-2 level 2) or PED-authenticated (FIPS 140-2 level 3)
- Both HSMs must be configured with the same cloning domain. This is an independent password or set of PED keys, distinct from “crypto-officer” or “crypto-user” credential required to use existing keys.
Strangely cloning works even when source/target HSM have different FIPS settings- it is possible to clone from an HSM in strict FIPS mode to one that is not. More surprisingly, it also works across HSMs with different firmware versions. So there is still an attack here: clone all keys from a fully-patched HSM to a vulnerable unit controlled by the attacker. Weak key-derivation algorithms will be enabled (on purpose) in this latter unit, allowing the attack to be carried out.
How serious is this risk? Cloning requires exactly the same access as working with existing keys in the HSM: for the USB connected Luna G5, that is a USB connection. For the SA7000 as featured in AWS CloudHSM, it can be done remotely over the network. In other words an attacker who compromises a machine authorized to use the HSM, they get this access for free. The catch is that an additional credential is required, namely the cloning domain. Unlike standard “user” credentials necessary to operate the HSM, cloning-domain is not used under normal operation, only when initializing HSMs. Compromising a machine that is authorized to access the HSM guarantees compromise of the user role (or “partition owner” role in Safenet terminology.) But it does not guarantee that cloning-domain credentials can be obtained from the same box, unless the operators were being sloppy in reusing same passphrase.
CP



You must be logged in to post a comment.