[continued from part I]
So what are the problems with Box enterprise-key management?
1. Key generation
First observe that the bulk data encryption keys are generated by Box. These are the keys used to encrypt the actual contents of files in storage. These keys need to be generated “randomly” and discarded afterwards, keeping only the version wrapped by the master-key. But access to the customer key is not required if one can recover the data-encryption keys directly. A trivial way for Box to retain access to customer data- for example, if ordered by law enforcement- is to generate keys using a predictable scheme or simply stash aside the original key.
2. Possession of keys vs. control over keys
Note that Box can still decrypt data anytime, as long as the HSM interface is up. For example consider what happens when employee Alice uploads a file and shares it with employee Bob. At some future instant, Bob will need to get a decrypted copy of this file on his machine. By virtue of the fact Box must be given access to HSMs, there must exist at least one path where that decryption takes place within Box environment, with Box making an authenticated call to the HSM.**
That raises two problems. The first is that the call does not capture user intent. As Box notes, any requests to HSM will create an audit-trail but that is not sufficient to distinguish between the cases:
- Employee Bob is really trying to download the file Alice uploaded
- Some Box insider went rogue and wants to read that document
While there is an authentication step required to access HSMs, those protocols can not express whether Box is acting autonomously versus acting on behalf of a user at the other side of the transaction requesting a document. That problem applies even if Box refrains from making additional HSM calls in order to avoid arousing suspicion— just to be on the safe side, in case the enterprise is checking HSM requests against records of what documents its own employees accessed, even though the latter is provided by Box and presumably subject to falsification. During routine use of Box, in the very act of sharing content between users, plaintext of the document is exposed. If Box wanted to start logging documents- because it has gone rogue or is being compelled by an authorized warrant- it could simply wait until another user tries to download the same document, in which case decryption will happen naturally. No spurious HSM calls are required. For that matter Box could just wait until Alice makes some revisions to the document and uploads a new version in plaintext.
3. Blackbox server-side implementation
Stepping back from specific objections, there is a more fundamental flaw in this concept: customers still have to trust that Box has in fact implemented a system that works as advertised. This is ongoing trust for the life of the service, as distinct from one-time trust at the outset. The latter would have been an easier sell because such leaps of faith are common when purchasing IT. It is the type of optimistic assumption one makes when buying a laptop for example, hoping that the units were not Trojaned from the factory by the manufacturer. Assuming the manufacturer was honest at the outset, deciding to go rogue at later point in time would be too late- they can not compromise existing inventory already shipped out. (Barring auto-update or remote-access mechanisms, of course.)
With a cloud service that requires ongoing trust, the risks are higher: Box can change its mind and go “rogue” anytime. They can start stashing away unencrypted data, silently escrowing keys to another party or generating weak keys that can be recovered later. Current Box employees will no doubt swear upon a stack of post-IPO shares that no such shenanigans are taking place. This is the same refrain: “trust us, we are honest.” They are almost certainly right. But to outsiders a cloud service is an opaque black-box: there is no way to verify that such claims are accurate. At best an independent audit may confirm the claims made by the service provider, reframing the statement into “trust Ernst & Young, they are honest” without altering the core dynamic: this design critically relies on competent and honest operation of the service provider to guarantee privacy.
Bottom line
Why single out Box when this is the modus operandi for most cloud operations? Viewing the glass as half-full, one could argue that at least they tried to improve the situation. One counter-point is that putting this much effort for negligible privacy improvement makes for a poor cost/benefit tradeoff. After going through all the trouble of deploying HSMs, instituting key-management procedures and setting up elaborate access-controls between Box and corporate data center, the customer ends up not much better than they would have been using vanilla Google Drive.
That is unfortunate because this problem is eminently tractable. Of all the different private-computing scenarios, file storage is most amenable to end-to-end privacy- after all there is not much “computing” going on, when all you are doing is storing and retrieving chunks of opaque ciphertext without performing any manipulation on it. Unlike solving the problem of searching over encrypted text or calculating formulas over a spreadsheet with encrypted cells, no new cryptographic techniques are required to implement this. (With the possible exception of proxy re-encryption; but only if we insist that Box itself handle sharing. Otherwise there is a trivial client-side solution, by decrypting and reencrypting to another user public-key.) Instead of the current security theater, Box could have spent about the same amount of development effort to achieve true end-to-end privacy for cloud storage.
CP
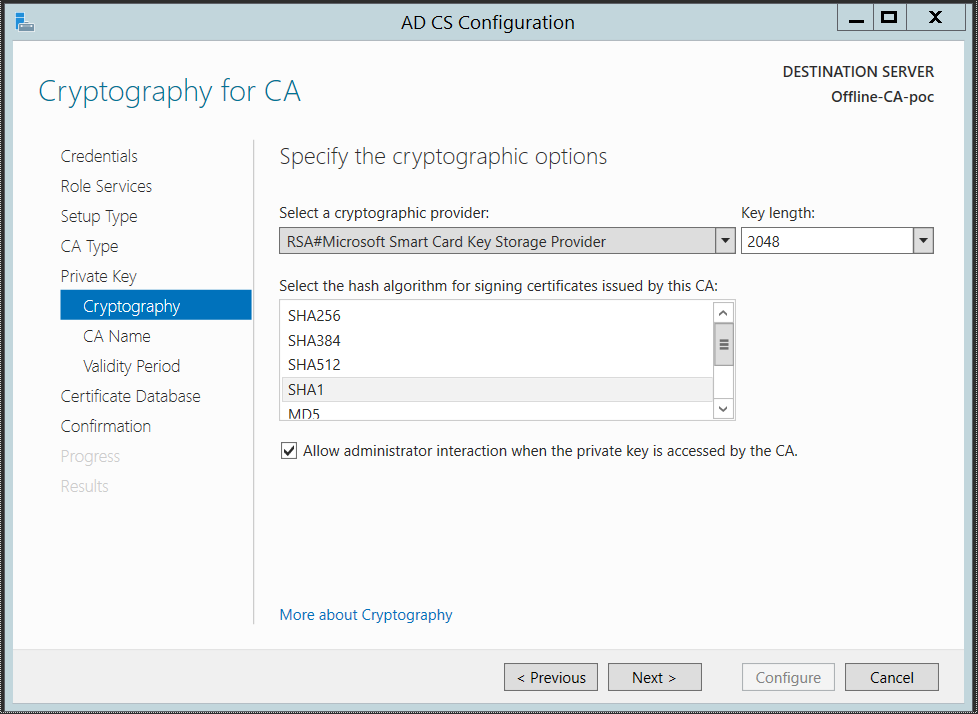
** Tangent: Box has a smart-client and mobile app so in theory decryption could also be taking place on the end-user PC. In that model HSM access is granted to enterprise devices instead of Box service itself, keeping the trust boundary internal to the organization. But that model faces practical difficulties in implementation. Among other things, HSM access involves some shared credentials- for example in the case of Safenet Luna SA7000s used by CloudHSM, there is a partition passphrase that would need to be distributed to all clients. There is also the problem that user Alice could decrypt any document, even those she did not have access to by permission. To work around such issues, would require adding a level of indirection by putting another service in front of HSMs that authenticates users via their standard enterprise identity, not their Box account. Even then there is the scenario for files from a web-browser when no such intelligence exists to perform on the fly decryption client-side.

{kind=link}
You must be logged in to post a comment.